In all this cold, I had occasion to heat some water for tea, watching the pot the whole while, and contrary to common belief, it boiled anyway.
We had a bunch of snow last night and this morning. It's just stopped in the last hour.



Your work is going to fill a large part of your life, and the only way to be truly satisfied is to do what you believe is great work. And the only way to do great work is to love what you do. If you haven't found it yet, keep looking. Don't settle... All external expectations, all pride, all fear of embarrassment or failure -- these things just fall away in the face of death, leaving only what is truly important. Remembering that you are going to die is the best way I know to avoid the trap of thinking you have something to lose. You are already naked. There is no reason not to follow your heart.I recently left a job where I wasn't following my heart. The money was good and the rest of the economy was bad, so I spent a lot of energy and effort trying to make it work, but there was no passion or fun or excitement. So this talk resonates for me now.


sudo yum install eclipse-jdt eclipse-cdt \ freeglut freeglut-devel kernel-devel \ mesa-libGLU-devel libXmu-devel libXi-devel
The Mac has this cool little utility called sample. Here's how it works. Suppose some program is running as process ID 1234. You type "sample 1234 60" in another terminal, and it interrupts that process 100 times per second for 60 seconds, getting a stack trace each time. You end up with a histogram showing the different threads and C call stacks, and it becomes very easy to figure out where the program is spending most of its time. It's very cool. It doesn't even significantly slow down the process under study.
I started looking to see if there was anything similar for Linux. There ought to be. This isn't so different from what GDB does. The closest thing I could find was something called pstack, which does this once, but doesn't seem so good at extracting the names of C routines. I've never seen pstack get a stack that was more than three calls deep. I also found a variant called lsstack.
I think the Mac can do this because Apple can dictate that every compile must have the -g switch turned on. The pstack utility came originally from the BSD world.
If there's ever a working sample utility for Linux, it will be a brilliant thing.
First you need a timer process that interrupts the target process. On each interrupt, you collect a stack trace. You do that by having an interrupt handler that gets the stack above it and throws it in some kind of data structure. In Mac OS, you can do all this without recompiling any of the target process code.
You run the timer for however long and collect all this stuff. You end up with a data structure with all these stacks in it. Now you can create a tree with histogram numbers for each node in the tree, where each node in the tree represents a program counter. Next you use map files to convert the program counters to line numbers in source files, and if you want brownie points, you even include the source line for each of them.
This should be feasible in Linux. Check out "man request_irq".
The only issue with making this work as well in Linux as it does on the Mac is that code that isn't built with "-g" will not have the debug information for pulling out function names and line numbers. Somebody (probably David Mosberger-Tang) has already done this project:
| Intel Barebones #2 | |||
| * Intel Pentium Dual Core E2220 2.4 GHz, 800FSB (Dual Core) 1024K | |||
| * Spire Socket 775 Intel fan | |||
| * ASRock 4Core1600, G31, 1600FSB, Onboard Video, PCI Express, Sound, LAN | |||
| * 4GB (2x2GB) PC6400 DDR2 800 Dual Channel | |||
| * AC 97 3D Full Duplex sound card (onboard) | |||
| * Ethernet network adapter (onboard) | |||
| * Nikao Black Neon ATX Case w/side window & front USB | |||
| * Okia 550W ATX Power Supply w/ 6pin PCI-E | |||
 Given the slowing of Moore's Law these days, it's good to be a GPU manufacturer. The GPU guys never claim to offer a parallelizing compiler -- one that can be applied to existing code written for a serial computer -- instead they just make it very easy to write new parallel code. Take a look at nVIDIA's GPU Gems, and notice there's a lot of math and very little code. Because you write GPU code in plain old C, they don't need to spend a lot of ink explaining a lot of wierd syntax.
Given the slowing of Moore's Law these days, it's good to be a GPU manufacturer. The GPU guys never claim to offer a parallelizing compiler -- one that can be applied to existing code written for a serial computer -- instead they just make it very easy to write new parallel code. Take a look at nVIDIA's GPU Gems, and notice there's a lot of math and very little code. Because you write GPU code in plain old C, they don't need to spend a lot of ink explaining a lot of wierd syntax.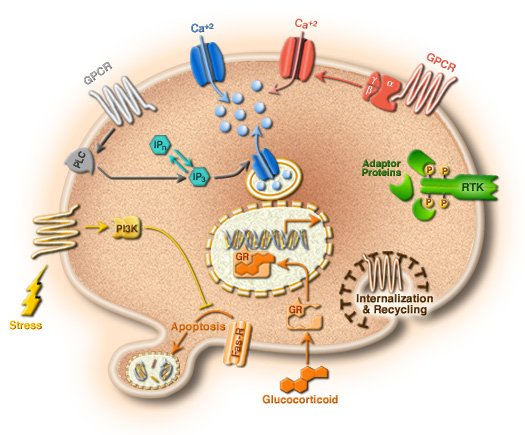 E-Cell is a software model of a biological cell. To use E-Cell (as it existed in its initial incarnation), you define a set of DNA sequences and chemical reactions, and the program iterates them over time, tracking the concentrations of different proteins and other goings-on in the cell.
E-Cell is a software model of a biological cell. To use E-Cell (as it existed in its initial incarnation), you define a set of DNA sequences and chemical reactions, and the program iterates them over time, tracking the concentrations of different proteins and other goings-on in the cell.They are oriented to making an impact on the field of robotics rather than making an immediate profit. Cousins explained it in these terms: the average robotics PhD student spends 90% of his time building a robot and the remaining 10% extending the state of the art. If Willow Garage succeeds, those numbers will be reversed.Neat. I'd love to get a chance to play with one.
 Hadoop is Apache's implementation of the MapReduce distributed computing scheme innovated by Google. Amazon rents out Hadoop services on their cluster. It's fairly straightforward to set up Hadoop on a cluster of Linux boxes. Having myself a long-standing interest in distributed computing approaches to molecular modeling, I have been trying to figure out how Hadoop could be applied to do very large-scale molecular simulations.
Hadoop is Apache's implementation of the MapReduce distributed computing scheme innovated by Google. Amazon rents out Hadoop services on their cluster. It's fairly straightforward to set up Hadoop on a cluster of Linux boxes. Having myself a long-standing interest in distributed computing approaches to molecular modeling, I have been trying to figure out how Hadoop could be applied to do very large-scale molecular simulations.Could the tasks that NAMD assigns to each machine be anonymized with respect to which machine they run on, and the communications routed through a distributed filesystem like Hadoop's HDFS? Certainly it's possible in principle. Whether I'll be able to make any reasonable progress on it in my abundant spare time is another matter.
Members of the official website can gain sponsor status for a fee of US$10 every six months. Sponsors can access videos a few days before the general public release, download higher-resolution versions of the episodes, and access special content released only to sponsors. For example, during season 5, Rooster Teeth began to release directors' commentary to sponsors for download. Additionally, while the public archive is limited to rotating sets of videos, sponsors can access content from previous seasons at any time.They are smart guys who have been doing this for years now, so it's likely they've hit upon as optimal a solution as is practical. Of course it helps that they have a great product that attracts a lot of interest. They are following the Borland approach: sponsorship is inexpensive and there is no attempt at copy protection.

 The Hunt for Gollum is a 40-minute high-def movie made by fans of the Lord of the Rings trilogy in general, and the Peter Jackson movies in particular. The trailers look beautiful, the cinematography looks about as good as the three movies. This is being done on a purely non-profit basis and the entire movie will be released free to the Internet on Sunday, May 3rd.
The Hunt for Gollum is a 40-minute high-def movie made by fans of the Lord of the Rings trilogy in general, and the Peter Jackson movies in particular. The trailers look beautiful, the cinematography looks about as good as the three movies. This is being done on a purely non-profit basis and the entire movie will be released free to the Internet on Sunday, May 3rd.The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood; who strives valiantly; who errs, who comes short again and again, because there is no effort without error and shortcoming; but who does actually strive to do the deeds; who knows great enthusiasms, the great devotions; who spends himself in a worthy cause; who at the best knows in the end the triumph of high achievement, and who at the worst, if he fails, at least fails while daring greatly, so that his place shall never be with those cold and timid souls who neither know victory nor defeat.Alright, enough gushing. But I really do love having this guy as my president.
— Theodore Roosevelt
 Dr. Eric Drexler founded the field of advanced nanotechnology with a 1981 paper in the Proceedings of the National Academy of Sciences, and his book Engines of Creation published in 1986. These two publications laid the intellectual foundation for a complete revision of human manufacturing technology. Like any major shift in technology, there are risks to be aware of, but the promise of advanced nanotechnology is vast: clean cheap manufacturing processes for just about anything you can imagine, products that seem nearly magical by today's standards, medical instruments and treatments far more advanced than today's medicine.
Dr. Eric Drexler founded the field of advanced nanotechnology with a 1981 paper in the Proceedings of the National Academy of Sciences, and his book Engines of Creation published in 1986. These two publications laid the intellectual foundation for a complete revision of human manufacturing technology. Like any major shift in technology, there are risks to be aware of, but the promise of advanced nanotechnology is vast: clean cheap manufacturing processes for just about anything you can imagine, products that seem nearly magical by today's standards, medical instruments and treatments far more advanced than today's medicine.